Versnellen van stochastische simulaties door Extreme Gradient Boosting
Het bepalen van best estimate voorzieningen voor levensverzekeringen vereist projecties naar de toekomst, waarbij de gebruikte parameters onzeker zijn. Want welke kosten worden er verwacht gedurende een periode? Hoe ontwikkelen de sterftekansen zich? En hoe groot moeten buffers zijn om onverwachte kosten op te kunnen vangen?
De impact van deze onzekerheden op de balans kan worden vastgesteld door een voorspelling te maken van de toekomstige kasstromen. Combinaties van grote portfolio’s en vele toekomstige paden kunnen resulteren in zware berekeningen, vooral als gebruik wordt gemaakt van een intern model. Door dit proces enkele malen zelf uit te voeren en de resultaten te gebruiken om een algoritme te trainen, zou veel tijdswinst geboekt kunnen worden. Een veelgebruikt Machine Learning algoritme staat bekend als extreme gradient boosting (XGBoost), welke op basis van data een betrouwbare, maar bovenal snelle, toekomstige kasstroom kan bepalen. In dit artikel wordt gekeken naar het bepalen van de best estimate liability (BEL) en de risico marge zoals beschreven door Solvency II aan de hand van extreme gradient boosting
Op basis van data een betrouwbare, maar bovenal snelle, toekomstige kasstroom bepalen
Sterftetafels
Een van de relevante onderdelen bij het bepalen van de kasstromen van een levensverzekering zijn de sterftekansen. De veelal gebruikte AG sterftetafel wordt door het AG bepaald aan de hand van een stochastisch model wat een voorspelling maakt voor de sterfte gedurende een periode. Met dit model kunnen de verwachte kasstromen bepaald worden. Door verschillende factoren zullen de vastgestelde kansen afwijken van de werkelijke kansen (welke pas na afloop van een periode te bepalen zijn). Door met verschillende sterftetafels te rekenen en voor deze allemaal de bijbehorende toekomstige kasstromen te bepalen, kan er op soortgelijke wijze een verdeling bepaald worden voor de kasstromen. Deze kansverdeling geeft voor elke boven- en ondergrens van kasstromen een bepaalde zekerheid.
Om het sterfteproces te simuleren zijn verschillende methodieken ontwikkeld, waaronder het Lee-Carter model. Dit model kan eenvoudig vele sterftetafels genereren aan de hand van historische data. Op de historische data wordt een tijdsreeks gekalibreerd welke de basis vormt voor gesimuleerde sterftekansen. De gesimuleerde kansen worden gebruikt om mogelijke toekomstige kasstromen te bepalen.
Machine learning
De combinatie van de sterftetafels en de berekende kasstromen vormen de input voor het Machine Learning algoritme. De meeste
Machine Learning algoritmes maken gebruik van zogenaamde loss-function. Een loss-function beeld de prestatie van een algoritme af
aan de hand van de afwijkingen tussen het voorspelde en het geobserveerde. Machine Learning algoritmes zoeken naar voorspellingen welke de loss-function minimaliseren. Een weak learner, zoals een decision tree, maakt een voorspelling op basis van de input. De loss-function geeft voor deze voorspelling de residuen, waarop een nieuwe decision tree gevormd kan worden. Door dit proces iteratief te herhalen kan er een betere voorspelling gemaakt worden dan wanneer er alleen één weak learner wordt gebruikt. Gradient boosting maakt gebruik van dit principe waarbij de loss-function geminimaliseerd wordt aan de hand van een Taylor-expansie. Hierbij wordt alleen rekening gehouden met de eerste orde Taylor-polynoom. Deze Taylor-polynoom wordt in dit geval geminimaliseerd door de eerste afgeleide van de loss-function vermenigvuldigd met een parameter. De combinatie van afgeleide en parameter vormen bij gradient boosting de residuen van de decision trees. Na elke iteratie kan onder andere een voorspelling worden gemaakt, waarmee over het algemeen geldt dat meer iteraties resulteren in een betere voorspelling over de gehele set. Extreme gradient boosting kent een soortgelijk proces, maar maakt gebruikt van de tweede order Taylor polynoom, mede hierdoor is het een efficiënt algoritme. Bovendien zijn er veel opties mogelijk waarmee schaalbaarheid en juistheid gewaarborgd blijven wat gebruikt kan worden voor accurate voorspellingen.
Een kleine trainingset resulteert in overfitting
Omdat dit proces de sterftekansen voorspelt kan er ingezoomd worden op een aantal onderdelen binnen Solvency II, zoals de BEL en de
solvabiliteit kapitaal vereisten (SCR) voor bijvoorbeeld mortality, longevity en catastroferisico. Aan de hand van het Lee-Carter model
worden sterftetafels gesimuleerd welke via de Standaard Formule de resulterende SCR’s en BEL bepalen. Door XGBoost uit te breiden naar
een multidimensionaal voorspellingsalgoritme kan de onderlinge samenhang van de onderdelen meegenomen worden in het trainen.
Resultaten
Om de resultaten te observeren zijn twee sets gecreëerd, de trainingset en de testset, waarbij elke tafel gebaseerd is op aparte parameters. De testset bestaat uit 1000 sterftetafels en de bijbehorende kasstromen, welke enkel worden gebruikt om de prestaties te bepalen. In bijgevoegde afbeelding is de grootte van de trainingset afgebeeld tegen de afwijking in de test set. Een te kleine trainingset resulteert in overfitting.
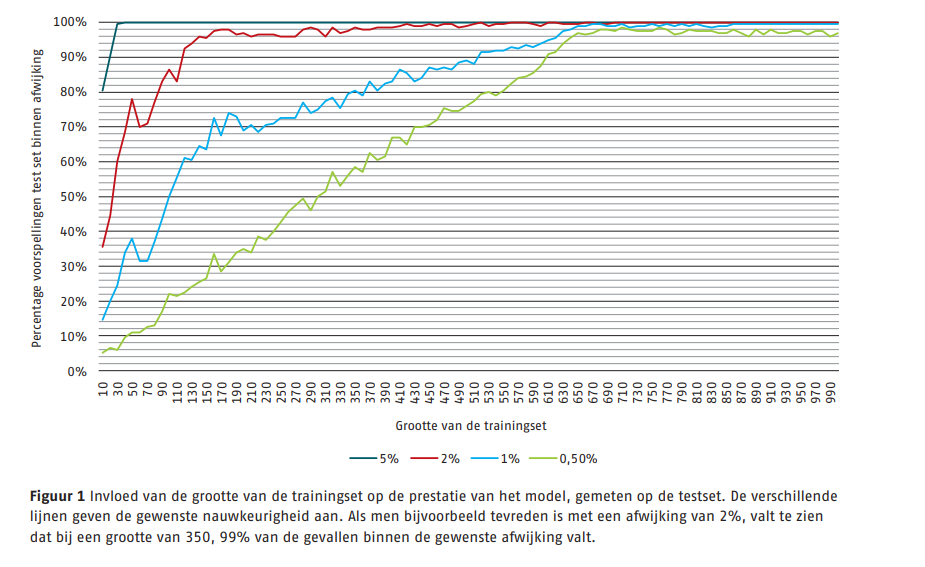
Hierdoor zijn resultaten voor die specifieke gevallen heel goed, maar resulteert dit in slechte voorspellingen voor de overige simulaties. Idealiter zou de trainingset zo divers mogelijk gemaakt zijn waardoor voorspellingen voor overige simulaties wel goed zijn. Het verkrijgen van een grote trainingset is echter een tijdsafhankelijk proces doordat er voor elk van deze sterftafels een voorspelling van kasstroom gemaakt moet worden. Er valt te zien dat vanaf een trainingset van ongeveer 650 tafels, 95 procent van de 1000 testcases zich binnen een afwijking van 0,5% bevindt. Deze prestatie wordt niet verder verbeterd door een grotere trainingset te nemen, bovendien zal een kleinere trainingset resulteren in een snellere kalibratie.
Het kalibreren van het model met een trainingset met grootte van 650 duurt ongeveer een halve minuut. Voorspellen van de testset is verwaarloosbaar, zelfs als de testset verveelvoudigd wordt. Het verkrijgen van de trainingsdata is echter een tijdrovend proces. Voor deze vergelijkingsanalyse is er voor de trainingset een periode nodig geweest van 5 dagen. Dit is een aanzienlijke tijd, maar als het model eenmaal gekalibreerd is, kunnen er oneindig veel voorspellingen gedaan worden. Zoals te zien in de afbeelding is met een zekerheid van 95% de afwijking binnen 0,5% voor de BEL. Als dit proces dus gebruikt wordt voor vele voorspellingen is een enorme tijdswinst te behalen zonder significant verlies van nauwkeurigheid.
Conclusie
Door eenmalig een XGBoost model te kalibreren kunnen later snelle beslissingen gemaakt worden op basis van het getrainde model en de voorspellingen. In dit geval ligt de focus hier op sterftetafels, welke naar vrije wil aangepast kunnen worden. Met een trainingset van 650 tafels bevindt 95% van de voorspellingen zich binnen een afwijking van 0,5%. Ofwel, na een eenmalige kalibratie, kan er voor een sterftetafel binnen enkele seconden een nauwkeurige voorspelling gemaakt worden. Dit zou uitgebreid kunnen worden naar kostenparameters of zelfs portefeuilles om een nog breder inzetbaar model te krijgen. Al met al zorgt dit voor een flexibel model met nauwkeurige resultaten en bovenal een aanzienlijke tijdwinst in het rapportageproces.
Dit artikel is geschreven door Sebastiaan van Schagen voor De Actuaris december 2024 editie.
-
Verder praten met
Triple A? E-mail
06 - 2273 9771
Wil je samenwerken met Triple A?
Spreken onze thema’s jou aan en is onze cultuur precies wat je zoekt? Kijk dan eens bij onze vacatures. Wij zijn altijd op zoek naar talent!
-

-
Wilt u meer informatie of een afspraak maken?
Neemt u dan contact op met Rian Katoen

Neem contact met mij op
© 2025 AAA Riskfinance. Alle rechten voorbehouden.